整理了一下实习时记录的有关于Unreal Engine 4的文档,共有两篇。
本文讲述了UE4内存分配器的抽象层次结构。
大纲
- 内存分配介绍
- 目标
- 常用分配方案
- 底层分配器介绍
- UE4 内存抽象层次
- 平台相关抽象层
- 分配器层
- 全局用户接口层
内存分配介绍
内存分配的目标
《游戏引擎架构》中将影响内存性能的提升点分为两方面:
- 调用
operator new/malloc的动态内存分配开销较大,使用自定制的内存分配器可以避免此开销。 - 内存访问模式会显著地影响一个程序的性能,让数据安排在小的、连续的内存块内可以有效地提高CPU的利用率。
这里主要谈的是内存分配,也就是第一点。
堆分配
malloc与operator new是C/C++中最低级的内存分配接口,是对操作系统堆分配的封装。既然涉及到操作系统API调用,就也会涉及到用户模式到内核模式的切换,开销很大。虽然一般的实现会自带内存块管理以减少进入内核模式的次数,但这种行为不可控,在实时性很高要求的时候可能带来严重的性能问题。另一方面,底层内存分配的实现以通用性为主,从几KB到几GB都要支持;而如果自己定制的话,就可以利用已有的分配需求,实现更高效的分配算法。
自定制内存分配的好处
-
自行维护可用内存,减少切换内核模式的次数。
-
针对特定的使用场景,对分配器的使用模式做出限定,进一步优化。
常用分配方案
- 全局分配:分配的内存在整个游戏启动期间均需要使用。
- 栈式分配:分配与回收以相反的顺序进行。
- 双端栈式分配:相比栈式分配更好地利用空闲内存。
- 池分配:每次分配固定大小的块,便于管理,也减少碎片。
- 单帧分配/双缓冲分配:利用游戏中每一帧分配的空间可以在下一帧/下两帧回收的特点,让帧内的临时分配(如异步处理)高效的完成。
- 动态分配:对分配和回收的大小和时间没有要求,如
malloc和operator new。
关于这几种分配器和相关的性能评估可见memory-allocators。
底层分配器介绍
在上述的分配方案中,动态分配仍然是最通用的一种。底层动态分配器从操作系统提供的堆空间分配接口(如Linux的brk/sbrk和Windows的HeapAlloc)获得空闲内存并进行管理,最后由malloc或operator new分配给上层的程序。由于底层动态分配器要有足有的通用性,也要解决诸如多线程并发分配、内存碎片等问题,不同的方案最后的综合的性能也各不同。
通用分配算法并不多,实际常用的有如下几种。
dlmalloc
又称Doug Lea’s Malloc,是Doug Lea从1987年开始编写并维护的一个分配器。
ptmalloc
全名pthreads malloc,在dlmalloc的基础上加入了对多线程的支持,是目前glibc的malloc实现。
Wolfram Gloger’s malloc homepage
jemalloc
有着在多线程下高性能、内存碎片少的优点,最早是FreeBSD libc的分配器,目前Facebook采用。
tcmalloc
Thread Cache Malloc是由Google为并发程序设计的分配器,其特点是通过per CPU/per thread的缓冲降低多线程分配的竞争,使得并行性能有很高的可扩展性。
mimalloc
Microsoft的一个较新的分配器,在其benchmark中综合性能超过了上述一众分配器。
更多关于分配器相关的资源可以见awesome-allocators。
UE4 内存抽象层次
UE4在内存分配上侧重动态分配的高效性,除了实现上述内存分配的目标,UE4还特别注重了跨平台和易用性两个方面。
类似文件系统,UE4的内存相关的操作也是通过多层抽象实现的。为了实现这几个目标,其大致可以分为以下3层:
- 平台相关抽象层(
FPlatformMamory) - 分配器层(
FMalloc) - 全局用户接口层(
FMemory)
它们的顺序也基本上是一个从底层封装到高层的关系。
平台相关抽象层
UE4为了适配各个不同的平台的内存分配接口,在**硬件抽象层(HAL)**定义了一层平台相关的内存操作接口,即PlatformMemory.h文件。其中定义了一个表示内存相关的接口的类FPlatformMemory,所有操作系统特定和平台特定的内存接口均封装在此类中。
正如硬件抽象层的其他接口,这些平台通用的逻辑实现在了GeneraicPlatformMemory.h下;而平台特定的接口定义则放在了XXXPlatformMemory.h下。后者中平台特定的类一般直接继承前者中通用的类,以实现功能的扩充。最后通过一个typedef完成在编译时替换平台接口的操作,比如在Windows平台的内存接口文件中的最后一行就有:
1 | typedef FWindowsPlatformMemory FPlatformMemory; |
在此时FPlatformMemory就已经指替为了平台特定的接口实现,后续直接使用即可。
UE4中绝大部分平台无关的接口均是由这种方式实现,由于在不同平台的头文件中有着不同的typedef定义,最后UBT在编译时只需要将合适的头文件include进来就可以了。事实上UE4专门定义了一个宏表示平台头文件的引入。如在
PlatformMemory.h文件中就有这一行,通过宏的拼接,根据UBT定义的平台宏将其更换为对应的头文件:
在GeneraicPlatformMemory.h中,定义了数个与内存相关的类:
FGenericPlatformMemoryConstants:存放描述一个平台内存相关常数的类,常数包括总内存大小、虚拟内存大小、页大小等。更高层的内存分配器可以利用这些信息来调优。FGenericPlatformMemoryStats:存放描述当前内存使用状况的类,如可用大小、已用大小等。FSharedMemoryRegion:表示一段共享内存区域。FBasicVirtualMemoryBlock:表示一个虚拟内存块。FGenericPlatformMemory:内存相关接口的集合,主要包括:- 初始化、设置内存池
- 处理Out of Memory异常
- 获得该平台上的基础分配器
- 获取统计信息、内存相关常数,Dump内存和分配器信息
- 对虚拟内存页面施加保护
- 从操作系统分配对齐的大块内存页面(用于Binned Allocator)
- 常规内存内存操作,如
Memmove、Memcmp、Memset、Memzero、Memcpy
它们基本上最后都会用上面提到的方法定义出实际使用的类,去掉开头的Generaic就是实际类的名字。
分配器层
从FPlatformMemory::BaseAllocator()可以获得平台上的基础分配器。分配器均继承自FMalloc。FMalloc可以看做是一切分配器的基类,其定义了分配器的基础接口,包括(Try)Malloc、(Try)Realloc、Free等虚函数。
分配器从功能上也可以分为几类:
- 平台底层分配器:一个平台上最底层的一层分配器,一般是OS上内存相关接口的直接封装。
- 功能修饰分配器:在底层分配器的基础上实现一些额外功能,如检测双重释放、检测泄漏、性能统计等等。
- 崩溃后备分配器:当遇到Out of Memory而崩溃时,不能再从平台底层分配器中申请内存。此时全局分配器会切换到一个预先分配好的后备分配器,以便完成错误信息收集与汇报等流程。
按照这种分层,可以比较清楚的看到各类分配器的作用:
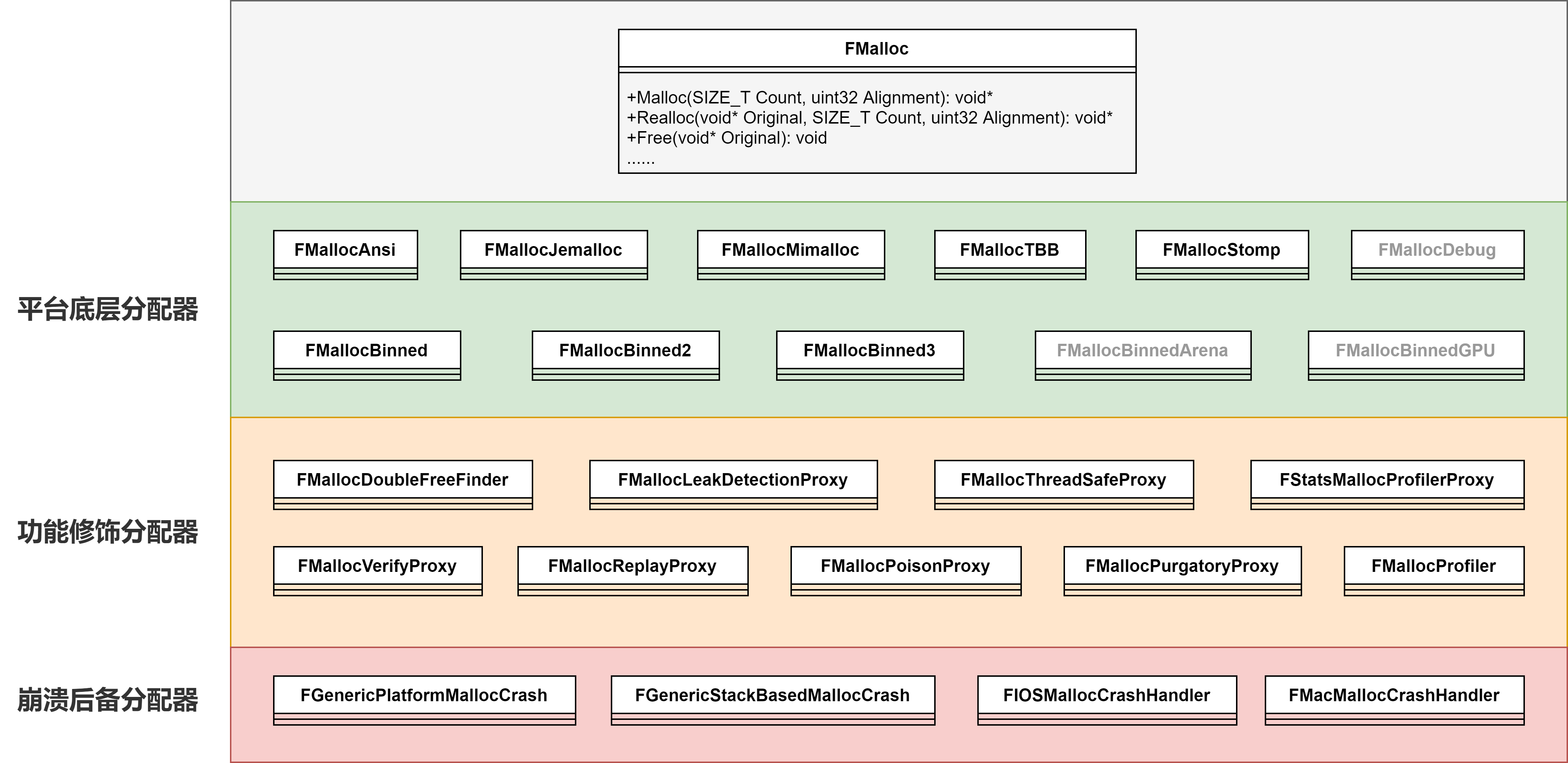
平台底层分配器
目前,可使用的底层分配器定义在如下的枚举中:
1 | enum EMemoryAllocatorToUse |
底层分配器的创建在每个平台自己的FXXXPlatformMemory::BaseAllocator()函数下创建,默认具体创建哪一个根据编译选项决定。各种平台下可以使用的分配器:
| 平台 | 可以使用的分配器 | 默认分配器(64Bits,游戏构建) |
|---|---|---|
| Windows | Ansi/TBB/Mimalloc/Binned3/Binned2/Binned/Stomp | Binned2 |
| Unix/Linux | Ansi/Binned2/Binned/Stomp | Binned2 |
| Mac | Ansi/TBB/Binned2/Binned/Stomp | Binned2 |
| IOS | Ansi/Binned2/Binned | Binned |
| Android | Binned3/Binned2/Binned | Binned2 |
在桌面端平台下,也可以通过启动命令行参数覆盖默认选择,如-stompmalloc就是使用Stomp分配器。
下面详细介绍每一种底层分配器。
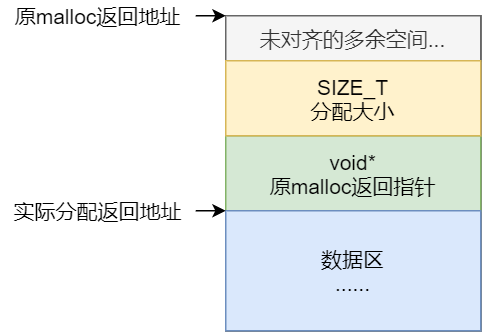
FMallocAnsi
实际分配使用C语言标准库malloc/realloc/free函数,FMallocAnsi通过分配一点额外空间来处理对齐问题。
解决对齐的做法和《游戏引擎架构》6.2.1.3中提到的一样:额外分配一个Alignment大小的空间,此外还有一个void*大小的指针记录实际从malloc取得的地址,和SIZE_T大小的变量表示分配大小以通过指针供反查询分配空间大小。在归还内存时,便可以通过对齐的指针反向查询出malloc原本返回的指针:
1 | void* originPtr = *((void**)((uint8*)Ptr - sizeof(void*))); |
其内存布局大致如下:
FMallocBinned2
在游戏引擎中,经常需要分配很多很小块的内存(几十bytes到几百bytes之间)。这些内存被频繁地分配释放,很容易导致大量的碎片问题,而UE4中的Binned Malloc就是为了解决内存碎片引发的性能问题。由于OS已经通过虚拟内存分页管理的方式解决了以页为单位的碎片,那么UE4就只需要解决小对象的分配就行了。
Binned的意思是“分箱”,意思是将小块的内存装在一个大箱中,便于管理。比如一个对象的大小是86 bytes,在实际分配时并不一定就按这个大小进行分配,而是将其放在一个比其大小稍大的箱子中,比如96 bytes的箱子。“分箱”的好处是减少了可能的分配大小数量,不需要再去考虑各种大小,只需要考虑几个预先确定下来的箱子大小。固定大小的另一个好处是非常便于用内存池的方式管理,进一步解决了碎片问题;此外也增加了内存复用,减少了调用OS内存分配这个较慢的操作。
箱子大小的确定是一个比较有技巧的事情,如果选择的不合适会导致内存空间的浪费过多。在FMallocBinned2中的SmallPoolTables表就记录了各种预先定义的箱大小,在分配一个特定大小的内存块时,会找一个与其最接近的箱子。箱子大小应该是分页大小的偶数因子,也需要让其做到16 bytes对齐,保证任何对齐要求都能被满足。目前箱子的大小共划分了45个档位:
1 | static uint16 SmallBlockSizes[45] = |
最低一档为16 bytes,最高一档为32768 - 16 bytes,只要分配大小小于最高一档,就采用这种分箱的分配方法。在分配时为了尽快找到最接近的大小档位,预先建立了一个查找表,并在BoundSizeToPoolIndex()中根据分配大小转换到箱大小。注意到其中有一些项减去了16,目的主要是预留额外空间,让块的地址满足对齐要求。
分配器对于箱内存的管理采用了内存池的方式,每一种箱大小对应一个内存池列表,而一个内存池实际上对应到一个逻辑页表。逻辑页表是Binned Malloc2分配器自己定义了一个内存单位,由多个连续的OS页表组成。目前一个逻辑页表的大小为64KB,在Windows下一个OS页表为4KB,也就是一个逻辑页表由16个连续的OS页表组成。
在每个内存池(逻辑页表)内,空间被分为以块为单位,每块的大小就是这个内存池的箱大小,其中的空闲块称作FreeBlock。在划分块的适合尽量要让多出来的剩余空间较小,这也是为什么前面在内存池分块时大小选定为分页大小的偶数因子。
内存池中空闲块的管理采用Free List方法,也就是链表结构,这里free的意思指链表的实际节点就储存在空闲块内部(类似intrusive list)。每当需要分配的时候就从链表头取出一个节点,释放时再挂回去。链表的节点由FFreeBlock描述,一个节点不一定只表示一个独立的块,而是可以直接表示多个连续的块。这样,在初始化时只需要处理一个节点即可。若一个FFreeBlock中有多个块,单个块的分配是从后往前分配的;而如果FFreeBlock只有一个块,就直接进行分配。
一个内存池的布局大致如下图所示:

在Binned Malloc2,从最上层的内存池列表到最下层的FreeBlock的管理,涉及到了几个结构:
-
FFreeBlock:空闲块链表节点,大小刚好为16 bytes(最小的一个箱大小)。其中记录了该块大小、在内存池中的序号、魔数(检验内存完整性)、此处连续的空闲块的块数,最重要的还是指向下一个
FFreeBlock的指针,以将池中的所有空闲块链起来。 -
FPoolInfo:描述一个内存池的信息,其中
FirstFreeblock指向第一个FFreeBlock节点。不同的内存池之间形成双向链表。 -
FPoolList:管理由
FPoolInfo组成的内存池信息列表。 -
FPoolTable:存放一种箱大小的
FPoolList,由于之前分了45档,FPoolTable也一共有45个。FPoolTable中将内存池分为活跃和非活跃的两种,对应到ActivePools和ExhaustedPools两种内存池列表。一旦一个内存池的块全部分配完毕,就认为其是非活跃的;而活跃的内存池一定是有非分配的空闲块的。活跃的内存池的已分配块全部清空后,可以将该内存池空间归还。
由于以上的结构为全局结构,在实际操作时需要加锁,多线程性能较差。为了并发分配的问题,Binned Malloc2还设置了一种线程局部块列表缓存FPerThreadFreeBlockLists,但线程归还某个块时,并不是直接还给内存池,而是先挂在这个缓存的块列表中。该缓存通过**TLS(Thread Loacl Storage)**实现,保证线程安全性。当缓存中的块数超过一个包(FBundle)的大小时,再批量地将这些块还给内存池。
当分配大小大于最大的箱大小时,会走另一条分配途径,直接从OS中分配连续的虚拟内存页面,具体的过程就不细说了。
此外,UE4还对OS分配的页表做了缓存(FCachedOSPageAllocator)。
整个Binned Malloc的实现,和Jemalloc、Mimalloc中的分配算法处理有不少相似之处。
一些更详细的介绍可以参考这篇文章。
FMallocBinned
Binned Malloc是Binned Malloc 2的上一代版本,目前默认只有IOS使用。
分配的思路和Binned Malloc 2相差不多,也是采用分箱和池的思想。按照分配的大小,共有4条分配路径:
-
Size <= SMALL_BLOCK_POOL_SIZE (256B)
IOS由于其硬件的内存较小,系统的分配器采用一些特殊的处理,将内存分配按大小分为nano、tiny、small、large几种类型,申请时按需进行最适分配。

在64位的IOS系统分配器中,对于小于256 bytes的分配会优先考虑nano分配。而在Binned Malloc中,也考虑了这一点,对于小于
SMALL_BLOCK_POOL_SIZE的分配大小(在IOS下SMALL_BLOCK_POOL_SIZE为256),会导向SmallOSAlloc分配路径,最后直接从系统的malloc中进行分配,也就是IOS的nano分配。至于nano malloc区的实际空间有多大,是在FMallocBinned的构造函数中试出来的:首先通过分配一块极小的内存得知nano区域的位置,然后再循环尝试获取nano的全部空间,统计出其大小。由于nano区域的地址是确定的,在free时可以判断指针是否来自nano区域,从而正确地归还给nano malloc。 -
Size <= BinnedSizeLimit (32KB)
根据分配大小找到最接近的箱大小,从内存池中取出一个箱子的空间用于分配,和Binned Malloc 2类似。这里的池的个数只有42种。
-
Size > BinnedSizeLimit && Size <= BinnedSizeLimit || Size > PageSize <= PageSize + BinnedSizeLimit
根据大小在两个有较大的块的池中选择进行分配,过程和2中的类似。
-
其他情况
对齐后直接调用OS的分配。
FMallocBinned3
为Binned Malloc 2的升级版本,其使用了PlatformMemory中提供的新接口,通过直接操作OS的虚拟地址,使得内存池索引和管理能够更高效地进行。
比如其先进行虚拟内存的保留,等到实际使用时才真正进行页面分配。
目前Binned Malloc 3只在Windows和Android上支持。
据称Epic在Fortnite中通过切换到Binned Malloc 3,将内存占用减少了几十MB。
FMallocTBB
使用Intel® Threading Building Blocks的分配器实现。
TBB分配器提供扩展性好的并行内存分配,防止多线程伪共享问题。
FMallocJemalloc
使用Jemalloc分配器实现。
FMallocMimalloc
使用Mimalloc分配器实现。Mimalloc是目前benchmark中最好的分配器实现,该分配器在2020年1月加入到UE4中。
FMallocStomp
缓冲区溢出检测分配器,可以用于发现如下的bug:
- 在分配区域的尾部之后读写
- 在分配区域的头部之前读写
- 在释放区域后读写(Windows下)
检测的方式是额外分配一个虚拟内存页面,并设置该页面的保护属性为不可访问,当写溢出时会触发操作系统保护。
Windows平台能够实现只分配虚拟地址而不分配物理地址的功能,可以用于保留已经分配过的虚拟地址,检测在释放后的读写操作。这种方式的副作用是造成OS页表项的大量分配。
Windows页表项使用VAD Trees管理,页表项只是描述这个页的信息,而实际的页不一定进行了分配。只要Windows在页表中保留了描述某个页范围的项,这个范围内的页就不会被分配给其他人。
功能修饰分配器
这类分配器只是在已有分配器的一层包装,依赖于已有的分配器(在构造时需要传入原分配器指针),以实现一些额外功能。功能主要为一系列相关检测、性能统计、线程安全等。
这里又用到了责任链设计模式
-
FMallocVerify:检验内存指针有效性,即检测释放时还给分配器的指针是不是真的分配过。 -
FMallocLeakDetectionProxy:实际上为FMallocLeakDetection的代理,检测内存泄漏。为了定位泄漏的地点,其内部采用了作用域记录的方式,用户代码配合
MALLOCLEAK_SCOPED_CONTEXT(Context)和MALLOCLEAK_WHITELIST_SCOPE()这两个宏来自定义作用域,以便于记录分配的作用域,更准确地定位泄漏位置。 -
FMallocPoisonProxy:“毒化”内存,即在分配后空间填充特殊字节0xcd,回收后空间填充0xdd。一些变量未初始化的问题可以比较明显地体现出来。 -
FMallocDoubleFreeFinder:检测指针被释放两次的问题。 -
FMallocThreadSafeProxy:给内存各种操作上锁,使其变为线程安全的。 -
FMallocReplayProxy:将所有的内存分配操作记录下来,记录在磁盘文件中,以便后续回放(可以用来比较不同的底层分配器实现)。目前只有Linux开启了该功能。
-
FMallocPurgatoryProxy:类似FMallocStomp检测已释放内存被写入的功能,但可适用于所有平台。实际上是将内存释放推迟了几帧,并在真正释放时检测是否修改过其中的内容。
-
FStatsMallocProfilerProxy:统计内存分配操作到线程统计信息中。 -
FMallocProfiler:内存分配性能剖析,将内存分配信息记录到文件中以供后续分析。
崩溃后备分配器
在PlatformMallocCrash.h中,定义了FPlatformMallocCrash类用于处理崩溃时的内存分配。根据编译选项,其相当于以下两个类中的一个:
FGenericStackBasedMallocCrash:不释放的栈式分配FGenericPlatformMallocCrash:针对小块内存使用池分配;大块内存只分配不释放。
后备分配器的空间在引擎启动之处,随着全局分配器的创建而预选分配好,保证在后备分配器可用后才进行任何动态分配。
全局用户接口层
FMemory是对引擎全局内存接口的一个轻量级封装,提供了供引擎其他部分实际调用的内存接口。
一些常规操作(如memcpy、memset等)基本上是直接转发到FPlatformMemory中。
至于分配操作,需要持有一个分配器的实例,这个实例就是GMalloc。其创建在FMemory_GCreateMalloc_ThreadUnsafe()函数中进行。创建的过程如下:
- 从
FPlatformMemory获得平台底层分配器 - 初始化崩溃后备分配器
FPlatformMallocCrash - 如果开启了性能统计,用
FMallocProfiler包装当前GMalloc - 如果当前
GMalloc不是线程安全的,用FMallocThreadSafeProxy包装,使其成为线程安全的 - 如果开启了指针有效性检验,用
FMallocVerifyProxy包装当前GMalloc - 如果开启了泄漏检测,用
FMallocLeakDetectionProxy包装当前GMalloc - 如果开启了内存毒化,用
FMallocVerifyProxy包装当前GMalloc - 如果开启了双重释放检测,调用
FMallocDoubleFreeFinder::OverrideIfEnabled()包装当前GMalloc
实际进行分配时,如果发现GMalloc实例还没有创建,就会调用上述函数进行创建(创建过程保证是线程安全的)。之后直接调用GMalloc->Malloc()等接口进行分配和释放。
综上,在UE4中需要动态分配内存时,均应该通过FMemory::Malloc等接口进行,若用operator new或C语言的malloc,就无法享受到UE4内存分配器带来的好处。